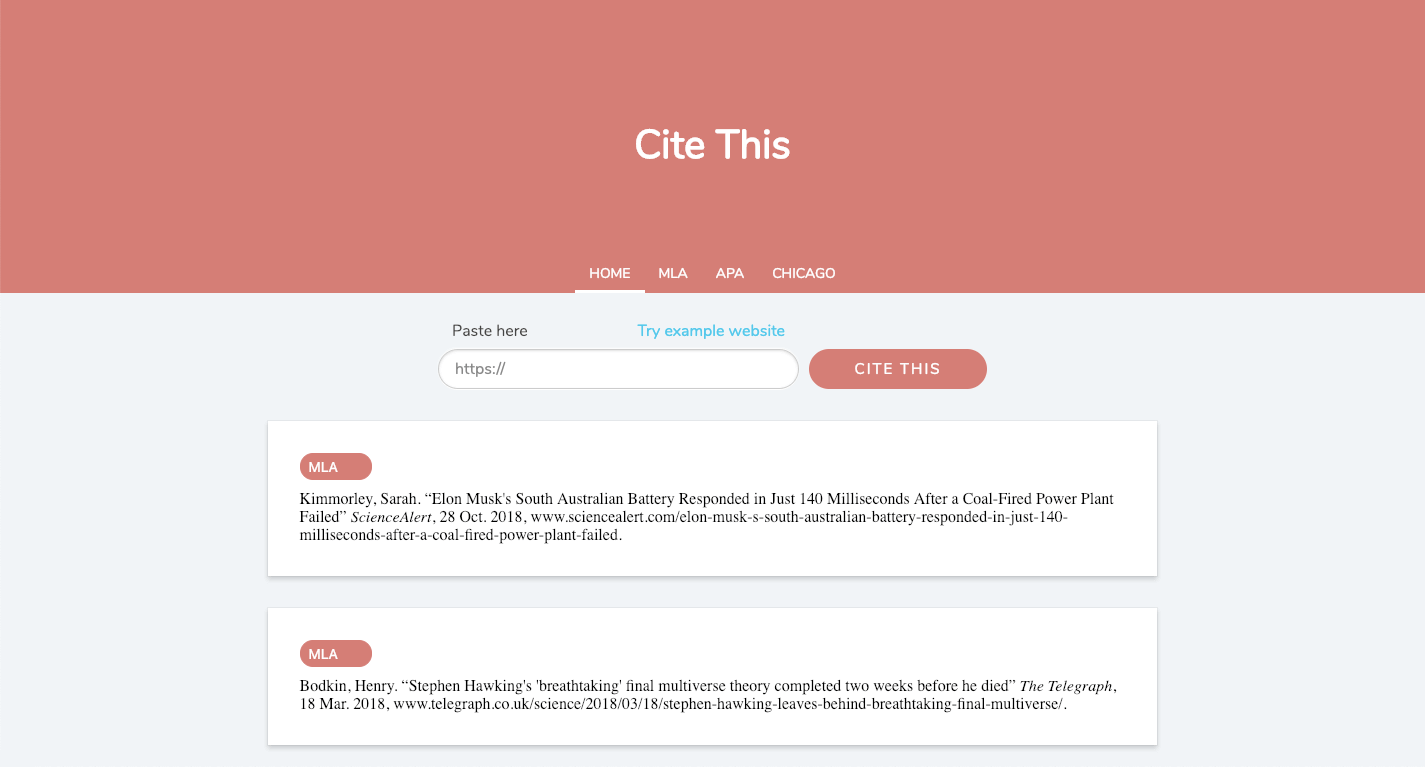
You can view this finished project live at citethis.net.
Cite what?
This is a citation generator designed to help students with their papers.
Starting in middle school and throughout high school and college, students write papers that require a list of sources. These sources must be cited in proper MLA/APA/Chicago syntax in order to get full credit for the assignment.
Many students, myself included, relied on online citation generators to get the finicky syntax correct.
Chegg's monopoly
The most popular citation generators are all owned by Chegg: easybib.com, citationmachine.net, citethisforme.com, and bibme.org.
And Chegg’s websites suck. They suck ass. Don't believe me? Look at these posts on Reddit's /r/assholedesign.
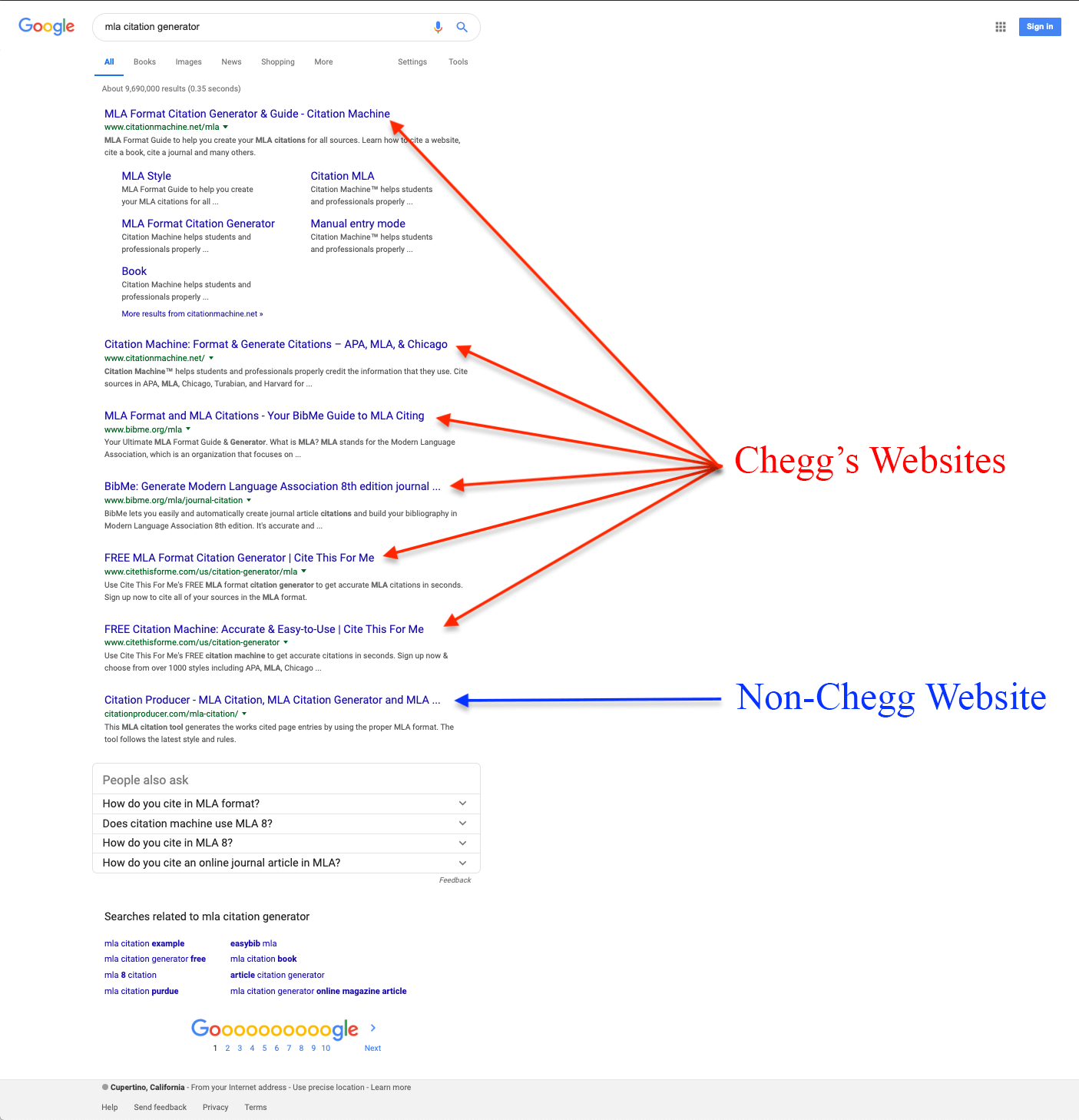
Below is a screenshot of a google search for "mla citation generator". As you can see, all but one of the results is owned by Chegg. And how often do you ever click on the very last result of a google search?
Creating my own citation generator
The citation generators on the first few pages of Google are all incredibly difficult to use.
- It takes 5+ minutes just to get a few citations
- Every page is cluttered with ads
- There are restrictions on how many citations can be generated
- They ask/force you to create an account
- They ask you to upgrade for an outrageous $10/month
And this is where I got my design requirements, prioritizing speed and usability.
- Be able to cite many websites within seconds
- No ads
- No restrictions
- No user signup
- Totally free
And so, citethis.net was born.
It's really, really fast
Citethis.net is the fastest citation generator on the entire Internet. Hands down.
From the moment that a URL is entered into the input field until the moment that the browser has the citation – with the author, date published and everything – is about 400 milliseconds. For previously crawled URLs, it's about 200 milliseconds (because it's cached into the database).
And this all happens when the user pastes a URL – not when the user clicks the cite button. By the time the user actually clicks the button, the citation is already in the browser, ready to be displayed.
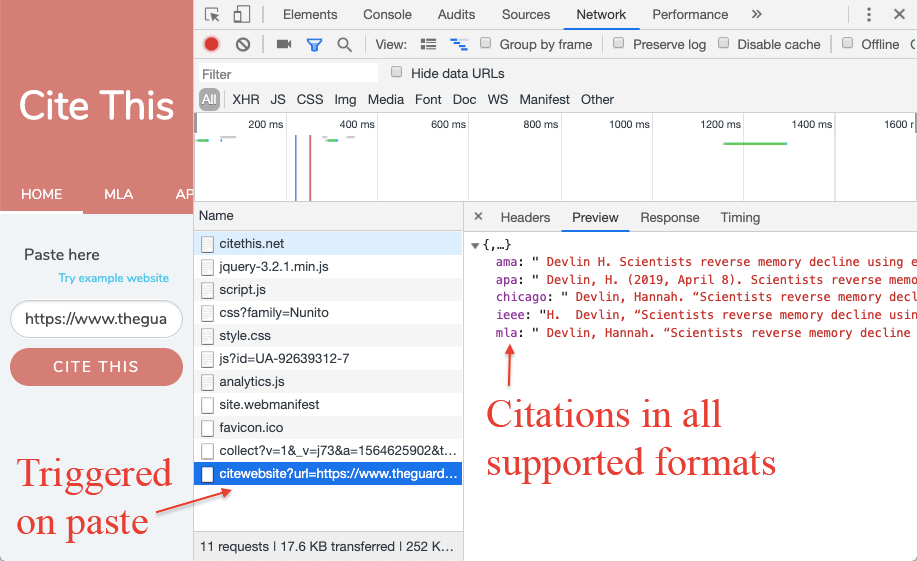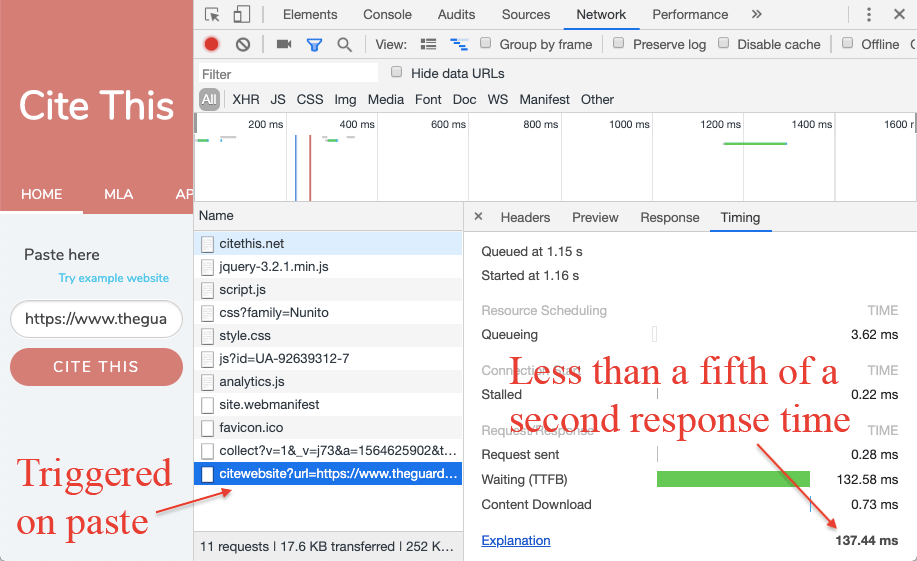
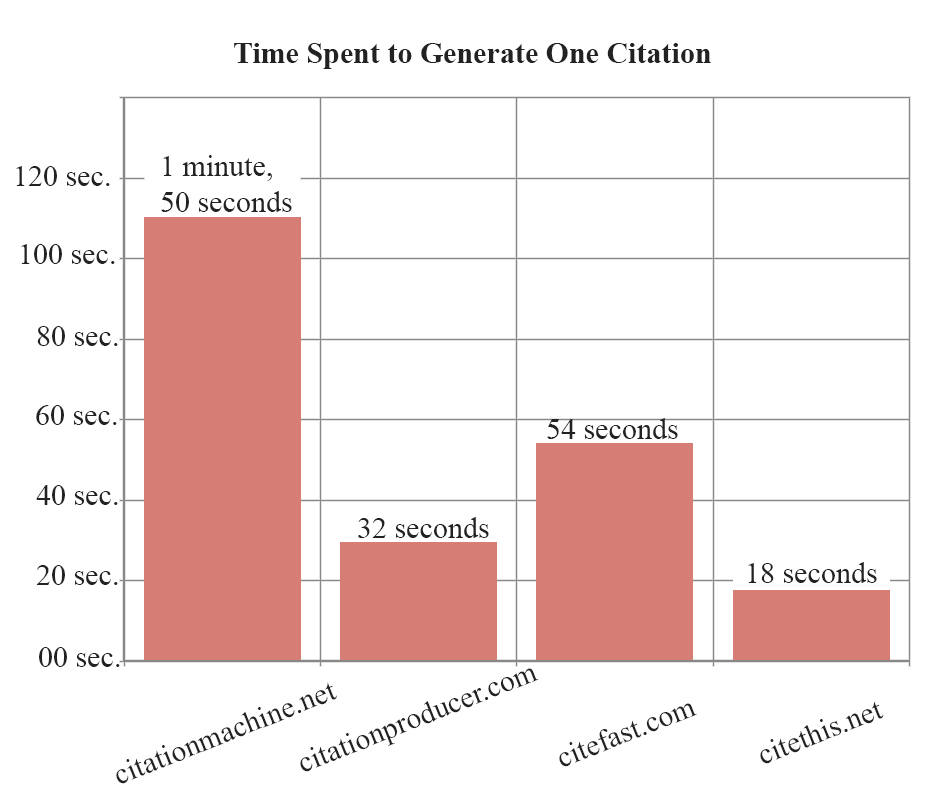
User testing: time spent
When users go to these sites, they have one thing on their mind: "I need a citation".
How long does that actually take?
To collect data on this, I conducted a test in which 3 users were instructed to cite a webpage in MLA and APA format using different citation generators.
You can see the full user test here: https://youtu.be/ZDnJCwV8vQQ
| Website | Quickest time | Longest time | Average time |
| citationmachine.net | 53 sec. | 3 min. 33 sec. | 1 min. 50 sec. |
| citationproducer.com | 22 sec. | 40 sec. | 32 sec. |
| citefast.com | 31 sec. | 1 min. 45 sec. | 54 sec. |
| citethis.net | 6 sec. | 32 sec. | 18 sec. |
Below is a graph showing average user times to generate a citation.
Data transferred for each citation
I grew up on a farm with a terrible internet connection (you'd be lucky to ever stream YouTube in 480p), so I'm very conscientious when it comes to loading page content. I know in today's age, everyone has a 6 MB parallax ultra HD fancy-framework website, but I like to keep it simple. (Guess how large this blog post is!)
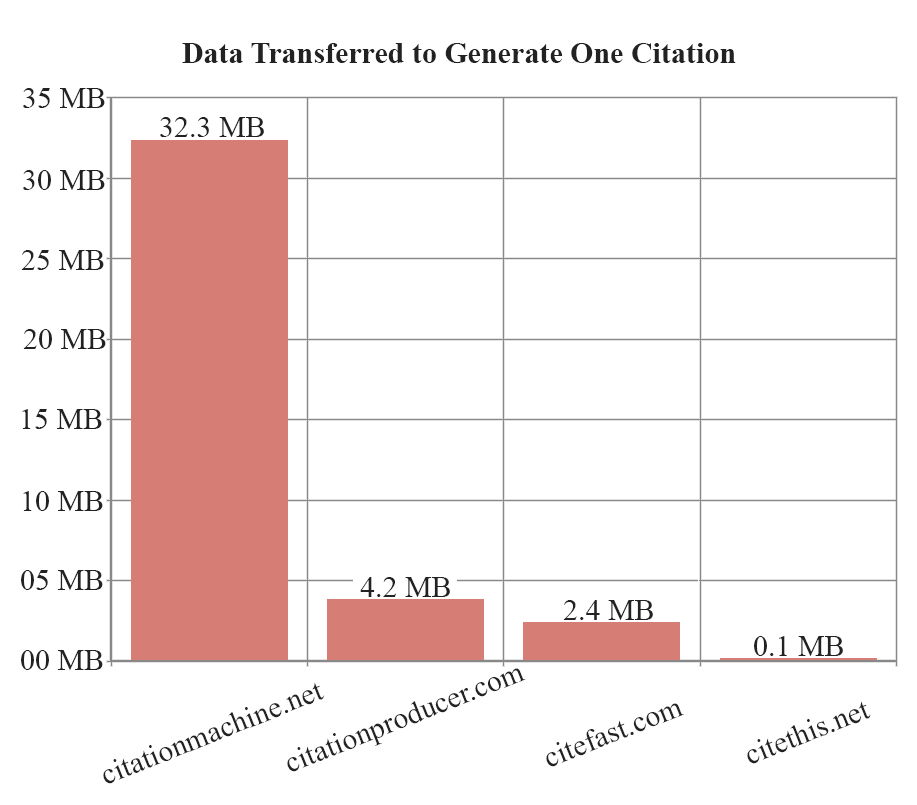
I recorded the amount of data that's transferred to generate a single citation, comparing my website to other websites.
You can see the full data here: https://docs.google.com/spreadsheets/d/1HG-aTB6BGECBIHyMwuC84WbDg2dnc5jmuXuhWoJIJqY
| Website | Number of requests | Data transferred |
| citationmachine.net | 2967 | 32.31 MB |
| citationproducer.com | 334 | 4.22 MB |
| citefast.com | 198 | 2.43 MB |
| citethis.net | 11 | 100.53 KB |
Languages and technologies
Trying to make this website lightweight, I wrote all of the HTML, CSS, and Javascript myself. The only library I used is jQuery, which allowed animating DOM manipulation to be a breeze.
I used PHP to serve the HTML. The website is simple enough that I didn't need any libraries or frameworks, and PHP got the job done with ease.
I chose Python for the crawler script because it's developer-friendly and it's versatile to use. The script parses HTML from a given URL, and finds the author, date published, article title, and website name. Libraries such as Flask, Requests and PyQuery made the task very duable.
For the database I used MySQL, because you can't go wrong with MySQL.
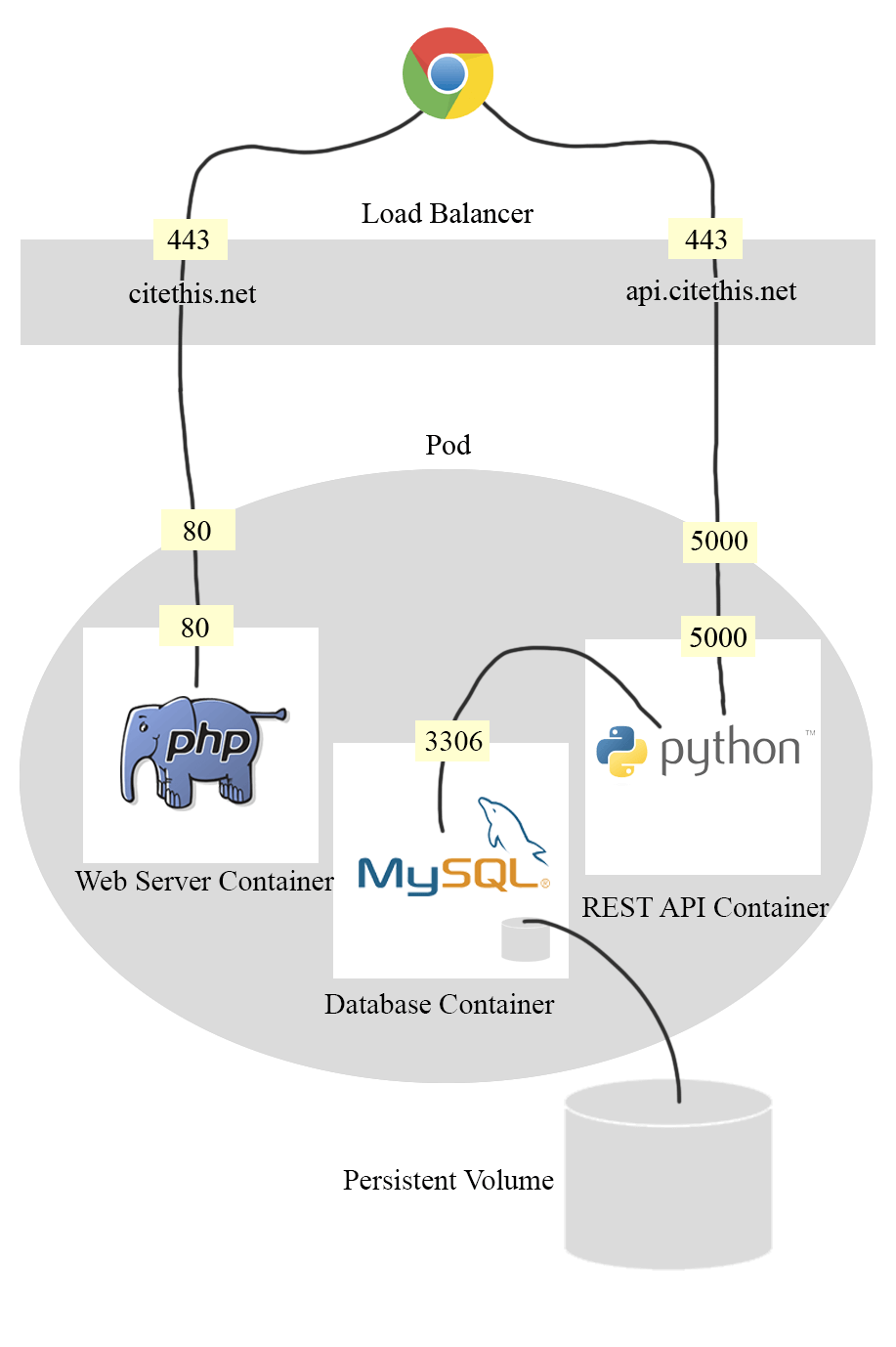
Microservice architecture
That's right. I said the M-word. Microservice.
If you're not familiar with microservices, I recommend watching this quick video that explains monolithic architecture vs microservice architecture: https://youtu.be/RJkn9VHM7lc.
Initially this website was hosted on my server, sharing apache and mysql with several other websites. Well one day apache crashes, taking down all of my websites. It took me 8 hours to realize they were down and to get them back up. 8 hours!
With containers (Docker), each website can have a dedicated apache and mysql instance. So if one website goes down, the others are still running.
With container orchestration (Kubernetes), each website can be restarted if anything goes wrong. If apache dies, the process will immediately be relaunched. Additionally, Kubernetes makes it easy for the service to be highly available.
Using container-based deployments also made it easy to create a CD pipeline. Commits to master now go directly to production, with the help of a github trigger and a jenkins pipeline. This allows me to focus my energy on developing the application instead of worrying about maintaining production.
Infrastructure as code (IAC) has also made my life easier. Everything from container resource allocation to SSL certificates are statically defined in YAML files alongside my application code.
Mistakes I made
Initially, I only supported MLA, APA, and Chicago formats because they were the most commonly used. But once I started asking for feedback from students, they asked, "Does it support IEEE format?". I quickly realized supporting only 3 formats would limit my audience, so I shifted the objective to instead support every single format.
Initially, this was also just a single page application. I didn't see a need for making this a multi-page website, and I wanted to keep it as simple as possible. However, I soon came to realize it's poor impact on SEO. Chegg's websites are ranked so highly largely because of the sheer amount of content they have, and I decided to take a lesson from them. I ditched the single page application and created a page for every format in an effort to improve SEO and to better organize content (manual citations).
One aspect of this project that significantly slowed me down was choosing the wrong tools for the job. I initially started this project years ago, and at the time PHP was the only backend language I was comfortable with. I wrote the entire crawl script in PHP, and it was so messy you'd think it had gone through a woodchipper. It was hacky and difficult to maintain.
If I were to redo it, I'd build the entire project using Django, a Python framework which organizes code following the model-view-controller pattern. Python is also the best language of choice for the crawler script. It just makes sense to be consistent, using only one language and one organization system.
Another thing that I did poorly was failing to create detailed mockups before developing the site. Too often I went straight to development before flushing out my idea, resulting in me having to redo nearly every aspect of the website. Very inefficient.
Conclusion
I am proud to have imagined an idea and seen it through to creation. I'm now watching the daily user count grow and I plan on improving this website for years down the line – fixing bugs, supporting more kinds of sources, and supporting more citation formats.
Thanks for reading!